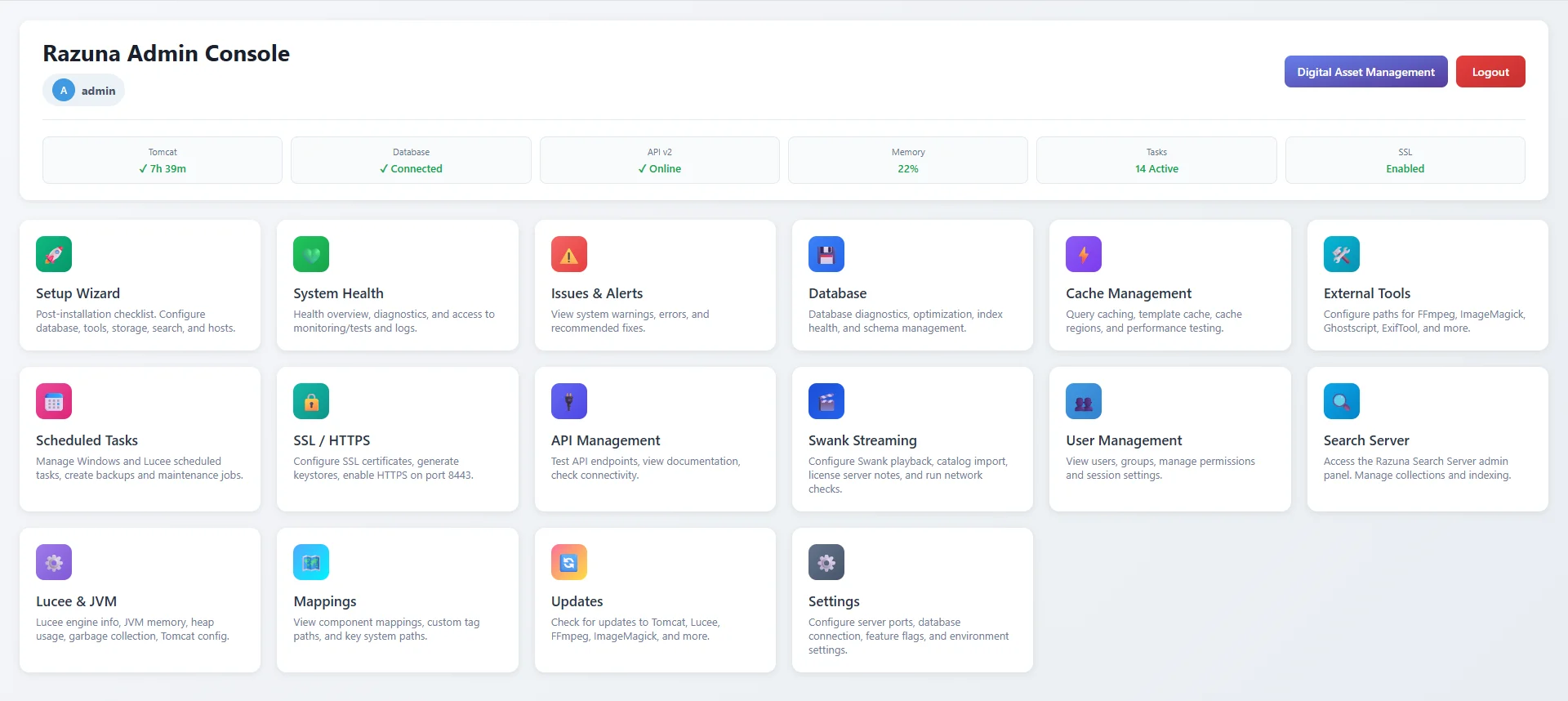
Razuna DAM Modernization (Open BlueDragon → Lucee 7)
Quick summary
- Performance: Reduced database round-trips by 92% by removing N+1 query patterns.
- Security: Upgraded legacy credentials from MD5 → BCrypt (cost 12) with transparent migration on login.
- Reliability: Replaced fragile file-based search indexing with a database-backed queue approach.
- Monitoring: Integrated Zabbix with JVM, service, health, disk, SSL, and error-rate checks for ops visibility.
- API docs: Delivered interactive docs via OpenAPI 3.0.3 (Swagger UI, ReDoc, Stoplight).
- Day-to-day ops: Added System Health + Logs, a scheduled maintenance task system, and a straightforward user/ops manual.
- Media analytics: Built-in playback, completion, and bandwidth tracking (bytes transferred) to support usage reporting and capacity planning.
- Integrations: Implemented an API2 webhook foundation for asset events to reduce polling and enable event-driven workflows.
Where it started: Razuna is an open-source DAM. This deployment needed to stay on-prem, but it was a Java 8-era stack: OpenBD (a discontinued CFML engine) embedded in the webapp, plus a dedicated search-server webapp, with JVM tuning baked into the “normal” deployment story and request routing that leaned on dispatchers and Fusebox-style fa=... “fuseactions” in the admin UI.
The pressure wasn’t “we want new.” It was compliance and risk. Java 8 was effectively end-of-life for our needs, which meant a growing list of CVEs we simply couldn’t close. In healthcare IT, that’s a non-starter: you can’t keep signing off on known issues in the runtime layer forever.
So the first move was pragmatic: drop in Java 9. It ran well enough to get us out of the worst of the Java 8 CVE hole, but it wasn’t a destination. Java 9 was already aging out, and the remaining runtime issues made the real question unavoidable: how do we get this onto a modern stack where we’re not constantly fighting EOL products?
I considered Java 11, but the timeline on that was already ticking. And if you’re going to do a “vastly different” jump anyway (8 → 11 is a different world than 8 → 9), you might as well buy runway. That’s why I aimed at Java 21: it gives the app a new lifeline and a long support window. From there, moving 21 → 25 wasn’t nearly as disruptive.
There was also a hard constraint: Lucee 7 requires at least Java 17. That ruled out 11 and made 21/25 the practical choices. Once the container/runtime baseline was stable, the OpenBD → Lucee 7 migration became achievable instead of a daily fire drill.
What we actually inherited (legacy CFML stack)
- CFML engine: OpenBD embedded in the webapp under
WEB-INF(its own release notes shipped with the app). - Runtime baseline: Razuna’s upstream docs for this era required Java 8 and a dedicated search-server webapp.
- Framework/routing: The admin UI was wired with Fusebox (fuseaction-style routing via an
faparameter), alongside multiple dispatcher-style entrypoints. - Operational footprint: JVM tuning was part of the “normal” deployment story, which matters when you move forward to a modern JVM with different defaults.
Chapter 1: Getting the platform back on solid ground
The first milestone sounded simple: make it run on a modern stack. In practice, it was a CFML archaeology project with a moving JVM underneath it. The “legacy specifics” mattered here: OpenBD-era CFML plus a Java 8 baseline meant the system had lived through PermGen, older GC defaults, and a lot of permissive behavior that modern engines/JVMs simply don’t tolerate. When we booted it under Lucee on a newer JVM, the failures weren’t subtle — they were loud and numerous enough to overload the runtime until we started systematically reducing the error rate and making startup deterministic again.
Routing was the other multiplier. This deployment wasn’t stock “one URL maps to one file.” It had dispatcher-style entrypoints (router templates) and a Fusebox-style request model in the admin UI (fuseactions via an fa parameter). On top of that, we had a custom router in front of a big slice of the app, which changed how templates were discovered and executed. So you couldn’t just fix a single failing .cfm and move on — you had to understand the request flow well enough to know why the engine was landing in a file in the first place.
Once we’d landed on a long-lived JVM baseline (Java 21 on Tomcat 11) and made startup repeatable, the OpenBD → Lucee 7 move became tractable instead of chaotic. After that, the Java 21 → 25 step was mostly validation: stricter bytecode verification surfaced CFML patterns that had been quietly tolerated for years. Fixing them wasn’t about “making the errors go away” — it was about getting predictable behavior under modern runtime rules.
The biggest early unlock was an API-first rebuild. We stripped out legacy APIv1 paths that were still half-present, then fixed and further enhanced APIv2 so integrations had one clear, supportable surface area. That work also forced the codebase through the router, auth gates, and error handling paths repeatedly - which is exactly what you want when you're trying to flush out brittle assumptions across lots of real request paths.
Constraints we codified (Lucee 7 compatibility)
- Template hygiene: Avoid invalid closing tags (e.g.,
</cfelse>,</cfelseif>,</cfset>,</cfinclude>) and standardize CFML comments (<!--- ... --->). - Includes vs URLs: Keep
<cfinclude template="...">paths app-root relative; only use the context path for user-facing links/forms. - Output boundaries: Close
<cfoutput>before logic blocks to prevent confusing parse errors (the classic “unterminated#” symptom). - Control flow: Enforce rules like
cfbreakonly inside loops; keep error handling explicit (cftry/cfcatch). - Query safety: Default to
cfqueryparamin touched code to avoid both injection risk and legacy string-concatenation edge cases.
What the migration actually looked like (small samples)
- Conflicting auth gates: In a couple API paths, a newer auth check succeeded and a legacy helper immediately rejected the same request. The fix was choosing one authority and removing the redundant blocker.
- Schema qualification: Standardized schema-qualified table references in touched queries to eliminate environment-dependent “invalid object name” failures.
- Naming/prefix assumptions: A few workflows relied on implicit naming conventions; making those rules explicit removed a class of hard-to-reproduce runtime errors.
Chapter 2: Security hardening
Once the platform was stable enough to trust, the next question was unavoidable: what would an audit find? The security review wasn't academic—this is the kind of system that ends up adjacent to sensitive data, and a small weakness can become a big incident.
Part of the work was proving what was already good: the data layer was overwhelmingly parameterized (thousands of parameterized queries), and the remaining high-risk paths were brought into line so fixes weren’t isolated patches—they were repeatable patterns.
The most immediate red flag was credential storage. Legacy accounts used MD5 hashing—a broken primitive by modern standards. Rather than forcing a disruptive cutover, I implemented BCrypt (cost factor 12) with a transparent migration path: when a user successfully logs in, their legacy hash upgrades automatically. Security improves from day one, without a mass reset and without breaking existing users.
From there, the work became about turning "known web-app failure modes" into solved problems: brute-force protection that locks out after 5 failed attempts (15 minutes), separate rate limiting lanes for login, API calls, and password resets, and closing account enumeration leaks where an attacker could infer whether an email exists from error text or timing differences.
Chapter 3: Database performance
With the platform modernized and safer, the next pain point was operational: under real usage, it felt slower than it should. Profiling and query analysis led to a familiar culprit—widespread N+1 query behavior where the ORM was quietly generating hundreds of round-trips that should have been a handful.
I treated it like detective work: identify the hot paths, reproduce the user flows, and then trace the database chatter back to the call sites. Across five major subsystems (DAM asset loading, custom fields, labels, collections, and folder operations), I refactored the data layer around batch queries and in-memory lookup maps. A concrete example: loading 25 assets with custom-field enrichment dropped from 26 queries (1 + 25) to 2 total—removing the latency spikes and cutting database round-trips by 92%.
Then I made the database work with the application instead of against it. Using SQL Server Query Store telemetry, I built indexes around real production query patterns: covering indexes like IX_AssetEvents_VideoStats and IX_AssetEvents_AssetLookup to eliminate key lookups, plus a filtered index on completion events that reduced index size by ~80% while keeping the hot reads fast. Query Store validation showed consistent sub-5ms execution times across core user flows.
Some wins were algorithmic rather than purely SQL. Folder operations were effectively O(n²)—nested loops that triggered a query per asset. I rewired those workflows to O(n) by issuing a single batch fetch with a WHERE IN clause and resolving values from a struct lookup. The result was immediate: folder browsing that took 2–3 seconds dropped under 200ms, even with hundreds of assets.
Chapter 4: Search reliability
Search was another "it works until it doesn't" subsystem. The legacy approach depended on file-based Lucene indexes that required manual maintenance and could drift or corrupt under operational stress. I removed Lucene from the deployment and moved indexing to a DB-backed queue (using razuna.search_reindex) so indexing became transactional, recoverable, and self-healing. On the runtime side, we leaned on a RAM cache for the "hot" lookups so search stayed responsive without relying on fragile files.
The migration exposed a deeper issue: this install had legacy search-server assumptions that weren't aligned with how stock Razuna behaves. It showed up when an upstream integration client couldn't reliably reach the search-server API. What looked like a connectivity problem initially turned into more "mismatch" work: request routing that didn't mirror upstream, legacy endpoints still being called, and search flows that assumed Lucene-era behavior.
Chapter 4 wasn’t just “swap the index.” The real work was making search deterministic end-to-end, then tightening the seams so other systems can call it without special casing. That included hardening index-run locking and cleanup to avoid overlapping runs, and putting a stale-lock TTL in place so a single bad run doesn’t wedge indexing until a human intervenes.
Deliberate scope reductions (keep it lean)
- No cloud dependencies by default: This deployment stays on-prem; features like S3/AWS aren't required (and can be accommodated when needed).
- No dedicated search host: Razuna’s search-server webapp runs within the same operational footprint; we don’t offload it to separate machines.
- Video-first focus: Razuna supports mixed media (audio/docs/etc.), but this deployment prioritized video workflows and reporting.
- Remove stock bloat: A number of default features were removed to keep the product smaller, easier to operate, and closer to what teams actually use.
Chapter 5: API usability and docs
Modernizing the internals only helps if teams can integrate with it confidently. The API existed, but the developer experience was essentially "read the source." I built an interactive documentation system around an OpenAPI 3.0.3 specification, including an automated export pipeline that transforms CFML API definitions into standards-compliant OpenAPI JSON.
To make it genuinely usable, I shipped three documentation viewers for different audiences: Stoplight Elements (modern browsing), ReDoc (clean three-panel layout), and Swagger UI (interactive testing). Integrations no longer require reading 4,000+ lines of CFML to understand request/response shapes—teams can test endpoints in-browser and generate client SDKs in any language.
To keep documentation from drifting, I packaged a repeatable workflow: a scriptable OpenAPI generation step, a lightweight “docs health” page to validate the JSON/viewers are live, and a set of copy/paste code examples so teams can get a first request working quickly.
Chapter 5.5: Webhooks for event-driven integrations
Beyond documentation, I added an API2 webhook foundation that supports subscriptions and scheduler-friendly delivery. Core asset events (create/update/delete) can enqueue deliveries, and a background worker can fan out events to external systems—reducing brittle polling and enabling real automation when teams are ready.
Chapter 6: Operating it in production
The last mile is where projects usually fail: production. I hardened the runtime as if it were a product, not a dev server—production-grade Tomcat 11 configuration, SSL/TLS posture, security constraints, and operational monitoring. Session management was tightened with 2-hour timeouts, secure cookie flags (httpOnly/secure/sameSite), and session rotation on authentication to mitigate fixation.
That hardening included the work that keeps teams out of trouble: tightening the Tomcat footprint (removing unnecessary admin surfaces), enforcing modern TLS, enabling HTTP/2, adding stuck-thread detection, and shipping a simple health endpoint that monitoring can check without scraping the full app. On the CFML side, I standardized structured, module-based logging with predictable rotation/retention so production incidents have an audit trail instead of a scavenger hunt.
Because this is commonly deployed as a Windows Service, I also documented the operational realities (service-managed JVM settings rather than a startup script) and built admin-side tooling for day-to-day ops—health checks, a safer log viewer (restricted roots, file-count caps), and settings that control log retention and maintenance behavior.
To keep the system running optimally, I built a first-class scheduled-task model that supports both application-level jobs (Lucee scheduled tasks) and host-level automation (Windows Task Scheduler). This covers the routine work that keeps production stable—asset and temp cleanup, cache maintenance, search reindexing, database stats refresh, and periodic database maintenance—while making it visible, controllable, and auditable from an admin UI.
On the usage side, I added built-in media telemetry so teams can answer practical questions without guesswork: what’s being played, how often, and what it costs in bandwidth. The resulting dashboards summarize playback and completion trends, bandwidth consumption over a selected window, and recent activity—useful for both capacity planning and incident triage.
One subtle challenge: many “direct asset” video URLs are served as static files by the container and never touch CFML, which means you can’t reliably track streaming in application code. To close that gap, I added a lightweight servlet filter to intercept video asset requests and record play events and bytes transferred without ever blocking the stream (silent failure on database issues). A small cleanup job resets stale “in progress” flags so dashboards stay accurate.
On the media side, I built an FFmpeg-based caption pipeline supporting both embedded subtitle tracks and burned-in captions, with Intel Quick Sync Video acceleration for encoding performance where available. At the OS boundary, I removed unsafe patterns like world-writable temp script generation and brittle command construction—reducing both security risk and operational surprises.
Once the platform was stable, we made the day-to-day operational story explicit: how CFML runs in this stack, what we monitor, and what tools exist to keep troubleshooting and setup repeatable.
CFML runs here as an embedded engine: Lucee inside Tomcat, running under the same Windows Service footprint as the app. For production behavior we keep template inspection off, use a dedicated RAM cache for hot-path lookups, and run the core housekeeping jobs from inside the runtime so day-to-day ops stays predictable.
This build is also intentionally Windows-first. Legacy Razuna supported Linux and we ran some Linux installs, but many hospital environments lean Windows-heavy (and some teams explicitly want to avoid Red Hat licensing costs). The deployment, scripts, and operational tooling reflect that reality.
Monitoring with Zabbix (what we actually watch)
- Availability: Windows service status, health endpoint reachability, and Razuna app availability.
- Database: Simple DB connectivity checks so "the app is up" doesn't hide "the app is broken."
- JVM pressure: Heap usage/percentage, thread counts, and GC activity pulled from Tomcat/JMX surfaces.
- Security + capacity: SSL certificate days remaining, free disk space, and recent log error counts.
- Ops ergonomics: A reusable Zabbix template with triggers and graphs so it plugs into standard monitoring instead of becoming a one-off dashboard.
Helper + setup wizard (built for real rebuilds)
- Admin-gated Helper: A built-in dashboard for diagnostics, environment checks, and targeted maintenance actions while we were stabilizing the platform.
- Faster troubleshooting: Quick checks for paths/permissions, DSN/JDBC sanity, log visibility, and focused smoke tests without digging through templates by hand.
- Better setup flow: A setup wizard that walks you through DSN selection/testing and schema patching so the platform can be stood up first and the database can be wired in cleanly when ready.
Impact
This modernization turned Razuna from "legacy software we keep alive" into a platform that starts clean, runs predictably, and is easier to operate day-to-day. We brought the runtime forward (Open BlueDragon → Lucee 7 on modern Java/Tomcat), cleaned up API surface area (APIv1 out, APIv2 hardened), and replaced fragile Lucene-era search behavior with a DB-backed indexing flow.
The practical payoff is fewer surprises. Ops has monitoring that fits into existing Zabbix workflows, troubleshooting is faster with the built-in Helper, and integrations have a clearer contract to build against. It's still Razuna, but it's been stripped down and tuned for the features this environment actually uses.